
백엔드 개발을 공부하다 보면 API 요청과 응답 흐름, Controller와 Service의 역할, 공통 응답 구조 같은 것들을 먼저 익히게 됩니다.
그런데 어느 정도 API를 만들기 시작하면 자연스럽게 다음 단계의 고민이 생깁니다.
“그래서 이 데이터를 DB에 어떻게 저장하고, 다시 어떻게 객체로 가져오는 걸까?”
저도 처음에는 repository.save()나 findById() 같은 메서드를 그냥 자연스럽게 사용했지만, 정작 그 내부에서 어떤 일이 벌어지는지까지는 깊게 생각하지 않았습니다.
하지만 JPA를 공부하다 보니, 단순히 편하게 데이터를 저장하고 조회하는 도구를 넘어서, 객체 지향 언어와 관계형 데이터베이스 사이의 차이를 메워주는 핵심 기술이라는 점이 보이기 시작했습니다.
특히 영속성 컨텍스트, 1차 캐시, 변경 감지, 지연 로딩 같은 개념은 처음에는 추상적으로 느껴졌지만, 흐름을 이해하고 나니 왜 JPA가 이렇게 많이 사용되는지 조금씩 이해할 수 있었습니다.
그래서 이번 글에서는 워크북 내용을 바탕으로 JPA가 왜 필요한지, 영속성 컨텍스트는 무엇인지, 엔티티와 연관관계는 어떻게 다뤄야 하는지, 그리고 JPQL은 어떤 식으로 사용하는지를 정리해보려고 합니다.
이번 글에서 다룰 내용은 다음과 같습니다.
- 객체 지향 언어와 관계형 데이터베이스의 차이
- JPA와 ORM은 무엇인가
- 영속성 컨텍스트란 무엇인가
- 1차 캐시, 변경 감지, 쓰기 지연 SQL 저장소
- 엔티티와 BaseEntity 설정
- 연관관계 매핑과 지연 로딩
- JPQL과 Repository 기반 조회 방식
객체 지향 언어와 관계형 데이터베이스는 왜 잘 안 맞을까?
자바는 객체 지향 언어입니다.
객체 지향 언어는 캡슐화, 상속, 다형성처럼 객체의 구조와 역할을 중심으로 설계됩니다.
반면 우리가 실제 데이터를 저장할 때 많이 사용하는 관계형 데이터베이스(RDBMS)는 테이블 구조와 데이터 정합성을 중심으로 설계됩니다.
즉, 둘은 출발점부터 다릅니다.
자바에서는 객체가 다른 객체를 참조하면서 관계를 맺습니다.
하지만 데이터베이스에서는 외래 키(FK)를 통해 테이블과 테이블이 연결됩니다.
예를 들어 DB에서는 store_id 하나로 가게와 미션을 연결할 수 있지만,
자바에서는 Mission 안에 Store를 참조로 들고 있어야 하고, 반대로 Store에서도 Mission을 보고 싶다면 또 별도의 컬렉션을 선언해야 합니다.
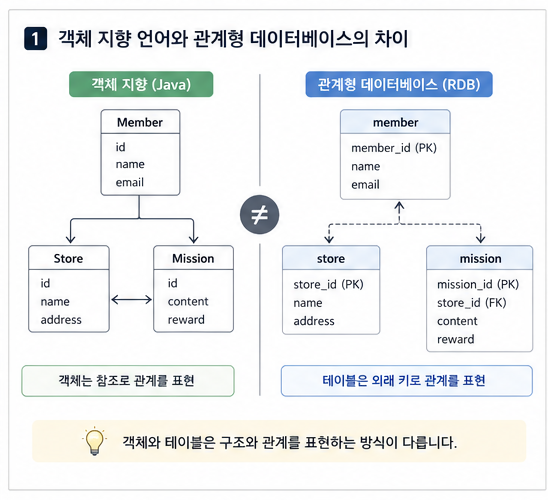
즉, 데이터베이스에서는 하나의 조인 키로 관계를 표현할 수 있지만, 객체에서는 관계를 어느 방향으로 볼지, 누가 주인이 될지를 따로 설계해야 합니다.
이 차이는 CRUD를 직접 작성할 때 더 크게 느껴집니다.
순수 JDBC로 회원가입 로직을 짠다고 생각해보면,
- 중복 회원 체크를 위해 SELECT를 작성하고
- 회원가입을 위해 INSERT를 작성하고
- PreparedStatement에 값을 하나씩 바인딩하고
- ResultSet을 다시 객체로 매핑해야 합니다
이 과정은 단순히 번거로운 정도가 아니라, 기능 하나를 만들 때마다 개발자가 직접 SQL과 객체 변환 작업을 반복해야 한다는 점에서 꽤 피로합니다.
그래서 공부하면서 느낀 건, 객체 지향 언어와 RDBMS는 둘 다 중요하지만 서로를 그대로 이해하지는 못한다는 점이었습니다.
그리고 바로 그 사이를 연결해주는 기술이 ORM이고, 자바 진영에서는 JPA가 그 중심에 있습니다.
JPA란?
JPA는 Java Persistence API의 줄임말입니다.
쉽게 말하면 자바에서 ORM 기술을 사용하기 위한 표준 인터페이스라고 볼 수 있습니다.
여기서 중요한 건 JPA가 곧바로 구현체 그 자체는 아니라는 점입니다.
JPA는 규약이고, 그 규약을 실제로 구현한 대표적인 오픈소스가 Hibernate입니다.
즉,
- JPA는 표준
- Hibernate는 구현체
이렇게 이해하면 훨씬 자연스럽습니다.
개인적으로 JPA를 처음 접했을 때는 그냥 “자바에서 DB를 쉽게 다루게 해주는 기술” 정도로 생각했는데,
정리하면서 보니 더 정확히는 객체와 테이블을 매핑해주는 표준적인 방법이라고 보는 게 맞았습니다.
ORM이란?
ORM은 Object Relational Mapping의 줄임말입니다.
말 그대로 객체와 관계형 데이터베이스를 매핑하는 기술입니다.

즉, 자바 클래스와 DB 테이블을 연결해두면, 개발자가 매번 SQL을 직접 짜지 않아도 객체 중심으로 데이터를 다룰 수 있게 도와줍니다.
예를 들어 Member 엔티티가 member 테이블과 매핑되어 있다면, 우리는 객체를 생성해서 save()만 호출해도 JPA가 알아서 INSERT SQL을 만들어 실행해줍니다.
조회할 때도 마찬가지입니다, DB의 row를 일일이 파싱해서 자바 객체로 변환할 필요 없이, JPA가 엔티티 객체로 매핑해줍니다.
그래서 ORM은 단순히 “쿼리를 덜 쓰게 해주는 기술”이 아니라, 데이터를 객체 중심으로 다룰 수 있게 만드는 방식에 가깝다고 느꼈습니다.
JPA 구조에서 가장 중요한 것: 영속성 컨텍스트
JPA를 이해할 때 가장 핵심이 되는 개념 중 하나가 바로 영속성 컨텍스트(Persistence Context) 입니다.
처음 이 단어를 들으면 꽤 어렵게 느껴집니다.
저도 처음에는 “영속적이라는 게 무슨 의미지?” 하고 막연하게만 받아들였습니다.
정리하자면 영속성 컨텍스트는 엔티티 객체를 관리하는 메모리상의 논리적 공간입니다.
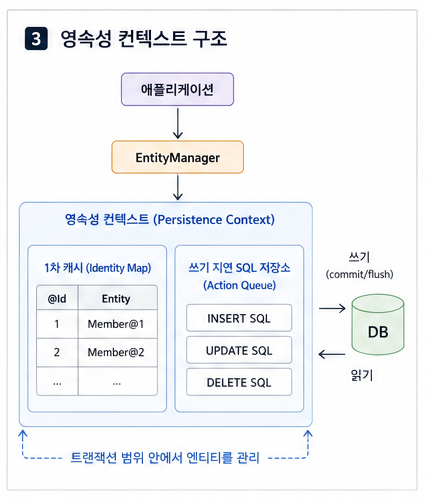
즉, JPA는 엔티티를 바로 DB에만 맡기는 것이 아니라, 먼저 이 영속성 컨텍스트 안에서 관리합니다.
쉽게 말하면, 애플리케이션과 데이터베이스 사이에 있는 가상의 중간 저장소 같은 역할을 한다고 볼 수 있습니다.
그리고 이 영속성 컨텍스트에 접근하는 주체가 바로 EntityManager입니다.
즉, EntityManager가 엔티티를 관리하고, 변경 내용을 추적하고, 필요한 시점에 DB에 반영하는 구조입니다.
영속 상태란 무엇일까?
JPA에서는 엔티티의 상태를 크게 네 가지로 나눕니다.
- 비영속
- 영속
- 준영속
- 삭제
이 중에서 가장 중요한 것은 역시 영속 상태입니다.
영속 상태란, 엔티티가 영속성 컨텍스트 안에서 관리되고 있는 상태를 말합니다.
즉, 단순히 객체를 만든 것만으로는 영속이 아닙니다.
JPA가 이 객체를 “내가 관리하고 있는 엔티티”라고 인식해야 영속 상태가 됩니다.
왜 이게 중요할까요?
엔티티가 영속 상태가 되면 JPA가 그 객체의 변화를 추적할 수 있기 때문입니다.
즉, 개발자가 직접 UPDATE SQL을 작성하지 않아도, 영속성 컨텍스트 안에 있는 객체가 수정되면 JPA가 그 차이를 감지해서 DB에 반영해줄 수 있습니다.
이 부분이 처음에는 굉장히 신기하게 느껴졌습니다.
객체를 수정했을 뿐인데, 커밋 시점에 SQL이 자동으로 나간다는 흐름이 바로 JPA가 가지는 강력한 장점 중 하나라고 생각했습니다.
영속성 컨텍스트의 장점: 1차 캐시
영속성 컨텍스트가 주는 대표적인 장점 중 하나는 1차 캐시입니다.
엔티티를 한 번 조회하면, 그 객체는 영속성 컨텍스트 안에 저장됩니다.
그 상태에서 같은 트랜잭션 안에서 동일한 엔티티를 다시 조회하면, JPA는 DB에 다시 쿼리를 날리는 것이 아니라 먼저 영속성 컨텍스트 안에 있는 객체를 반환합니다.
즉, 같은 데이터를 여러 번 조회하더라도 매번 DB에 가지 않아도 되는 것입니다.
예를 들어 어떤 Member를 한 번 조회한 뒤 같은 ID로 또 조회하면, 두 번째 조회는 DB가 아니라 영속성 컨텍스트의 1차 캐시에서 처리될 수 있습니다.
이 덕분에 성능적으로도 이점이 있고, 같은 트랜잭션 안에서는 같은 엔티티를 일관된 상태로 다룰 수 있다는 장점도 있습니다.
영속성 컨텍스트의 장점: 변경 감지(Dirty Checking)

JPA의 대표 기능 중 하나가 바로 변경 감지(Dirty Checking) 입니다.
이 기능 덕분에 영속 상태의 엔티티는 값을 수정하기만 해도, 트랜잭션이 끝나는 시점에 JPA가 변경 내용을 자동으로 감지합니다.
예를 들어 어떤 회원 엔티티를 조회한 뒤 이름을 바꿨다고 해보겠습니다.
Member member = em.find(Member.class, 1L);
member.setName("UMC10기최고");
이 시점에서는 아직 DB에 바로 UPDATE가 나가지 않습니다.
하지만 트랜잭션이 커밋되는 순간, JPA는 영속성 컨텍스트 안에 저장된 원본 상태와 현재 상태를 비교하고, 변경된 부분이 있으면 UPDATE SQL을 생성해서 실행합니다.
즉, 개발자는 객체를 수정했을 뿐인데, JPA는 그걸 DB 반영 대상 변경 사항으로 인식하는 것입니다.
이걸 보고 나니 왜 JPA가 객체 지향적으로 데이터를 다룬다고 하는지 조금 더 이해가 됐습니다.
직접 SQL을 호출하는 방식이라기보다, 객체 상태의 변화를 중심으로 DB를 업데이트하는 방식에 더 가깝기 때문입니다.
영속성 컨텍스트의 장점: 쓰기 지연 SQL 저장소
영속성 컨텍스트는 1차 캐시와 함께 쓰기 지연 SQL 저장소라는 개념도 가지고 있습니다.
이름만 보면 조금 복잡하지만, 의미는 비교적 단순합니다.
JPA는 엔티티를 저장하거나 수정할 때마다 즉시 DB에 SQL을 보내지 않고, 트랜잭션 커밋 시점까지 SQL을 모아둡니다.
그리고 flush() 또는 commit() 시점에 한꺼번에 실행합니다.
즉,
- 객체는 먼저 영속성 컨텍스트에서 관리되고
- SQL은 쓰기 지연 저장소에 모였다가
- 나중에 한 번에 DB로 나갑니다
이 구조 덕분에 JPA는 더 효율적으로 SQL을 관리할 수 있습니다.
정리하면서 느낀 건, 1차 캐시와 쓰기 지연 저장소는 따로 떨어진 개념이 아니라 영속성 컨텍스트가 객체를 관리하는 방식의 일부라는 점이었습니다.
엔티티를 만들 때 왜 BaseEntity를 둘까?
엔티티를 설계하다 보면 여러 테이블에서 공통적으로 들어가는 필드들이 있습니다.
예를 들어,
- 생성일시
- 수정일시
- 삭제일시
같은 필드들입니다.
이걸 엔티티마다 계속 반복해서 작성하면 코드가 불필요하게 길어지고 관리도 어려워집니다.
그래서 보통은 이런 공통 필드를 BaseEntity 같은 상위 클래스로 분리해서 사용합니다.
그리고 각 엔티티가 이를 상속받도록 설계합니다.
이때 자주 함께 사용하는 어노테이션이 있습니다.
- @MappedSuperclass
- @EntityListeners(AuditingEntityListener.class)
- @CreatedDate
- @LastModifiedDate
이런 설정을 해두면 엔티티 저장이나 수정 시점에 생성일, 수정일을 자동으로 채울 수 있습니다.
특히 @EnableJpaAuditing까지 함께 설정하면, 반복적으로 작성해야 하는 공통 필드를 훨씬 깔끔하게 관리할 수 있습니다.

이 부분은 실제 프로젝트를 하다 보면 꽤 실용적으로 느껴집니다.
작은 코드 차이 같지만, 엔티티가 많아질수록 공통 필드를 분리해두는 구조의 장점이 분명해지기 때문입니다.
엔티티 연관관계는 어떻게 설정할까?
JPA를 공부하면서 가장 헷갈리는 부분 중 하나가 연관관계 매핑입니다.
특히 처음에는 @ManyToOne, @OneToMany, @OneToOne, mappedBy, 연관관계의 주인 같은 개념이 한꺼번에 나와서 꽤 복잡하게 느껴집니다.
기본적으로 많이 사용하는 관계는 다음과 같습니다.
- @ManyToOne
- @OneToMany
- @OneToOne
그리고 외래 키를 실제로 관리하는 쪽에는 @JoinColumn을 설정합니다.
예를 들어 중간 테이블이 있고, 그 테이블이 회원과 음식 카테고리를 참조한다면 @ManyToOne으로 두 엔티티를 연결할 수 있습니다.
이때 중요한 것은 연관관계의 주인입니다.
데이터베이스에서는 FK가 있는 쪽이 관계를 관리하지만, 객체에서는 단순히 참조만 있다고 해서 자동으로 관계가 저장되는 것이 아닙니다.
즉, 객체 세계에서는 누가 이 관계를 실제로 DB에 반영할 것인지를 정해줘야 합니다.
이 지점이 객체와 테이블이 가장 다르게 느껴지는 부분 중 하나였습니다.
즉시 로딩과 지연 로딩
연관관계를 설정할 때 함께 고민해야 하는 것이 바로 로딩 방식입니다.
대표적으로 두 가지가 있습니다.
- FetchType.EAGER
- FetchType.LAZY
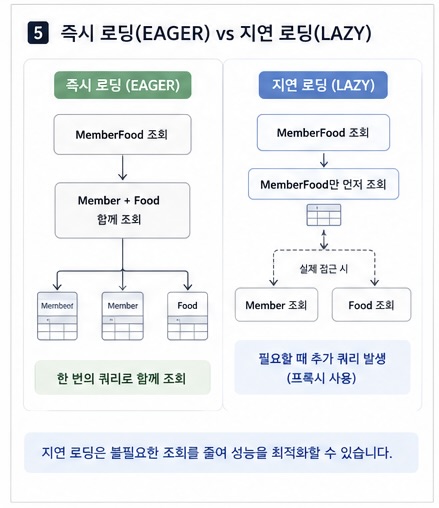
즉시 로딩(EAGER)
즉시 로딩은 말 그대로 연관된 객체를 한 번에 같이 조회하는 방식입니다.
예를 들어 MemberFood를 조회할 때, 연관된 Member와 Food도 함께 가져옵니다.
처음에는 한 번에 다 가져오니까 편해 보일 수 있습니다.
하지만 필요하지 않은 데이터까지 함께 불러오게 되면 쿼리가 무거워질 수 있고, 상황에 따라 N+1 문제도 발생할 수 있습니다.
지연 로딩(LAZY)
지연 로딩은 연관 객체를 바로 조회하지 않고, 실제로 사용할 때 조회하는 방식입니다.
즉, 처음에는 프록시 객체만 들고 있다가, 정말 필요한 시점에 DB 조회가 일어납니다.
그래서 일반적으로는 즉시 로딩보다는 지연 로딩을 기본으로 사용하는 것이 더 권장됩니다.
개인적으로도 공부하면서 느낀 건, 즉시 로딩은 편해 보여도 예상치 못한 쿼리를 만들 수 있어서 조심해야 하고, 지연 로딩은 의도를 더 명확하게 가져갈 수 있다는 점이었습니다.
양방향 매핑은 왜 할까?
연관관계는 단방향으로만 설정할 수도 있고, 양방향으로도 설정할 수 있습니다.
양방향 매핑을 하면 장점이 분명히 있습니다.

첫 번째는 그래프 탐색이 쉬워진다는 점입니다.
즉, A에서 B를 보고, B에서도 다시 A를 볼 수 있게 됩니다.
두 번째는 cascade 설정이 가능하다는 점입니다.
예를 들어 회원이 삭제될 때 그 회원과 연결된 중간 엔티티들도 함께 삭제하고 싶다면, cascade = CascadeType.REMOVE같은 설정을이용할 수 있습니다.
이런 경우에는 회원 하나만 삭제해도 연관된 데이터가 함께 정리됩니다.
다만 여기서 중요한 점은, 양방향 매핑과 cascade를 너무 쉽게 남용하면 안 된다는 것입니다.
잘못 설정하면 유저를 삭제했을 때 유저가 만든 게시글, 댓글, 연관된 다른 데이터까지 예상치 못하게 함께 삭제될 수 있기 때문입니다.
그래서 연관관계는 무조건 양방향으로 두는 것이 아니라, 정말 함께 관리되어야 하는 관계에만 신중하게 설정하는 것이 중요하다고 느꼈습니다.
JPQL이란?
JPA를 사용하다 보면 save()나 findById() 같은 기본 메서드만으로는 부족한 순간이 옵니다.
조금 더 조건이 있는 조회나, 복잡한 검색이 필요해질 때 사용하는 것이 바로 JPQL입니다.

JPQL은 SQL과 비슷하지만, 차이가 있습니다.
SQL은 테이블을 대상으로 쿼리를 작성합니다.
반면 JPQL은 엔티티 객체를 대상으로 쿼리를 작성합니다.
즉, DB 테이블 중심이 아니라 객체 중심의 쿼리 언어라고 볼 수 있습니다.
이 부분이 JPA의 철학과도 잘 맞습니다.
데이터베이스를 직접 다루기보다, 엔티티를 중심으로 조회를 설계하는 방식이기 때문입니다.
Repository에서 JPQL을 사용하는 방법
Spring Data JPA에서는 JPQL을 두 가지 방식으로 자주 사용합니다.
1. 메서드 이름으로 쿼리 생성
Spring Data JPA는 메서드 이름만 보고도 쿼리를 생성해줍니다.
예를 들어 이름이 “마크”이고, 삭제되지 않은 회원을 조회하고 싶다면 이런 식으로 메서드를 만들 수 있습니다.
findByNameAndDeletedAtIsNull
그러면 Spring Data JPA가 이 이름을 해석해서 조건에 맞는 JPQL을 자동으로 만들어줍니다.
이 방식은 간단한 조회에서는 굉장히 편리합니다.
2. @Query 어노테이션 사용
조금 더 복잡한 조건이 필요하거나, 직접 쿼리를 제어하고 싶다면 @Query를 사용할 수 있습니다.
이 방식은 조건이 복잡하거나 성능 최적화가 필요한 경우에 더 유리합니다.
또한 nativeQuery = true를 사용하면 JPQL이 아니라 실제 SQL을 직접 실행할 수도 있습니다.
즉, Repository는 단순히 기본 CRUD만 제공하는 것이 아니라, 메서드 이름 기반 조회와 직접 쿼리 작성까지 함께 지원하는 계층이라고 볼 수 있습니다.
이번 내용을 정리하며 느낀 점
이번 JPA 내용을 정리하면서 가장 크게 느낀 점은, JPA는 단순히 SQL을 덜 쓰게 해주는 도구가 아니라는 점이었습니다.
처음에는 save(), findById()가 편하다는 정도로만 느껴졌는데, 조금 더 들여다보니 그 안에는 객체와 데이터베이스 사이의 차이를 줄이기 위한 꽤 많은 설계가 들어 있었습니다.
특히 인상 깊었던 부분은 세 가지였습니다.
첫 번째는 영속성 컨텍스트입니다.
처음엔 추상적이었지만, 1차 캐시와 변경 감지, 쓰기 지연이 모두 여기서 출발한다는 걸 이해하고 나니 JPA의 핵심이 훨씬 잘 보였습니다.
두 번째는 지연 로딩의 중요성입니다.
연관 객체를 무조건 함께 조회하는 것이 아니라, 필요한 시점에 가져오는 설계가 실무에서 왜 중요한지 조금 더 이해할 수 있었습니다.
세 번째는 연관관계 매핑이 생각보다 조심해야 할 부분이 많다는 점입니다.
양방향 매핑과 cascade는 분명 편리하지만, 관계를 잘못 설계하면 예상치 못한 결과를 만들 수 있다는 점이 꽤 인상 깊었습니다.
마무리
이번 글에서는 JPA가 왜 필요한지부터 시작해서, ORM의 개념, 영속성 컨텍스트, 1차 캐시와 변경 감지, 연관관계 매핑, 그리고 JPQL까지 기본적인 내용을 정리해보았습니다.
정리하고 보니 JPA는 단순히 데이터를 쉽게 저장하고 조회하는 기술이 아니라, 객체 지향 애플리케이션과 관계형 데이터베이스 사이의 간극을 줄여주는 핵심 기술이라고 느껴졌습니다.
특히 영속성 컨텍스트를 중심으로 엔티티를 관리하고, 변경을 감지하고, 필요한 시점에 SQL을 실행하는 구조를 이해하니 그동안 무심코 사용했던 save()나 findById() 같은 메서드도 조금 다르게 보이기 시작했습니다.
앞으로 JPA를 사용할 때도 단순히 편리한 기능으로만 받아들이기보다, 왜 이런 구조로 동작하는지를 함께 이해하면서 사용하는 습관을 가져야겠다고 생각했습니다.